
How I ran LLMs on Steam Deck (Handheld Gaming Console)
Steam Deck is amazingly hackable

I recently got a Steam Deck, Valve’s handheld gaming console. It runs on SteamOS, a Linux-based operating system. What’s really cool about the Steam Deck is its versatility. Not only is it great for gaming on the go, but you can also connect it to a TV or monitor using a docking station. This turns it into something like a desktop computer or a home gaming console, which is pretty handy.
The core of the Steam Deck is the Van Gogh APU, blending AMD’s Zen 2 CPU and RDNA 2 GPU architectures. This combination is smart because it balances good performance with the need to save power for a handheld device. Even though the CPU isn’t as strong as in some other devices, the GPU part is great for gaming.
One thing I love about the Steam Deck is how customizable it is. Being based on Linux, it lets tech enthusiasts and developers like me try out different Linux distributions and use the device in various ways. This flexibility was a big help, especially for my work with running the Llama inference, which I’ll talk more about next.
Setting Up the Development Environment
Setting up the Steam Deck for development was a bit of a challenge at first. I tried to use Ubuntu alongside SteamOS, but I ran into trouble with the graphics after installing ROCm drivers. I was not able to boot in. I tried fixing it using GRUB, but no luck.
Then I found a simpler solution: using Distrobox to run Ubuntu 22.04. This worked out much better. For the ROCm drivers, I followed a guide I found on Reddit, which got everything installed just right. Check the following instructions for setting up.
Check this page for switching to desktop for setting up environment
Press the Steam button to bring up the Steam menu. Scroll down and select Power.
Select Switch to Desktop.
Wait for your Deck to switch to Desktop Mode. The setup would look like below.
Open Konsole for terminal and start executing following steps:
Install Distrobox and Podman
mkdir ~/.local/distrobox/
curl -s https://raw.githubusercontent.com/89luca89/distrobox/main/install | sh -s -- --prefix ~/.local/distrobox/
curl -s https://raw.githubusercontent.com/89luca89/distrobox/main/extras/install-podman | sh -s -- --prefix ~/.local/distrobox/Add below code to your .bashrc and reopen the shell
export PATH=$HOME/.local/distrobox/bin:$PATH
export PATH=$HOME/.local/distrobox/podman/bin:$PATH
xhost +si:localuser:$USERNow create Ubuntu container using Distrobox
distrobox create -i ubuntu:22.04
distrobox enter ubuntu-22-04Install RoCm
Once inside distrobox, install some utilities in Ubuntu
sudo apt update
sudo apt install build-essential
sudo apt install libnuma-dev
sudo apt-get install wget gnupg2Let’s install RoCm, AMD’s GPU drivers/programming environment
wget http://repo.radeon.com/amdgpu-install/latest/ubuntu/jammy/amdgpu-install_5.7.50700-1_all.deb
sudo apt install ./amdgpu-install_5.7.50700-1_all.deb
sudo apt update
sudo amdgpu-install --usecase=rocm,hip --no-dkmsAdd below lines to .bashrc file and source it. AMD Van Gogh GPU is officially not supported (version 10.3.3) by RoCm 5.7 so we have to override RoCm with closest supported RDNA2 GPU (version 10.3.0).
export PATH=$PATH:/opt/rocm/bin:/opt/rocm/rocprofiler/bin:/opt/rocm/opencl/bin
export HSA_OVERRIDE_GFX_VERSION=10.3.0Once the installation is done, reboot the Distrobox system
exit
podman stop ubuntu-22-04
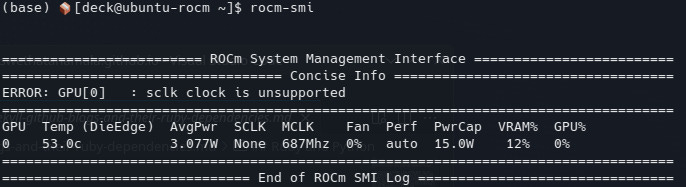
distrobox enter ubuntu-22-04We can check using below commands if rocm is installed correctly
rocm-smiIt should look like this:
Run Llama.cpp
Next, I worked with the Llama.cpp repository, which I cloned onto the Steam Deck from this GitHub link. For the llama-7b-model, I used this other GitHub link. You need a special access token from Meta to download it though.
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make LLAMA_HIPBLAS=1I ran Llama.cpp on both the CPU and GPU. The Steam Deck’s VRAM is limited to 1GB, so I couldn’t load the full llama-7b-model. I tried using the --n-gpu-layers parameter to load only some layers.
./main -m models/stablelm-3b-4e1t-Q4_K_M.bin -p "Building a website can be done in 10 simple steps:\nStep 1" -n 400 -e --n-gpu-layers 4Then I tested smaller models to see the difference between running them on the CPU and GPU. So, I tried the llama2.c stories110M model from Hugging Face. Converted them to llama.cpp format using this tool. Since this is a small model, I was able to fit everything in the GPU memory.

There’s not much difference between CPU and GPU because model is pretty small.
Increase GPU Memory (!)
The Van Gogh APU architecture in the Steam Deck is a unique system-on-chip design that combines AMD's Zen 2 CPU and RDNA 2 GPU in a single die. This is not too different from earlier Integrated Graphics and more recent Apple M1 chip. One of the most interesting aspects of such an architecture is how it manages memory. Unlike traditional systems where the GPU has dedicated VRAM, the Van Gogh APU uses shared memory. This means the GPU utilizes part of the Steam Deck's overall RAM as its VRAM. What's clever about this setup is that it allowed me to change memory allocation to GPU in BIOS. Follow this video:
I changed the option UMA frame buffer in BIOS to 4 GB. This reserved 4 GB of memory to GPU. Since total memory is fixed, memory available to CPU will now be limited to 12 GB. While this might have implications for gaming performance, this is amazing for running LLMs!
Lllama2-7b model with int4 quantization didn’t fit in 4 GB GPU memory because display and RoCm drivers would take out some of the GPU memory. So, I switched to the stablelm-3b-4e1t model from Stability AI. I found hugging face models which already converted these models to llama.cpp (gguf) format. Once downloaded, I ran this model both on CPU and GPU.
# CPU
./main -m models/stablelm-3b-4e1t-Q4_K_M.bin -p "Building a website can be done in 10 simple steps:\nStep 1" -n 400 -e --n-gpu-layers 0
# GPU
./main -m models/stablelm-3b-4e1t-Q4_K_M.bin -p "Building a website can be done in 10 simple steps:\nStep 1" -n 400 -e --n-gpu-layers 35Here’s how it looks:
Here are benchmarks:

As you can see, model runs roughly two times faster on GPU compared to CPU.
Conclusion
My experience with the Steam Deck has been quite an adventure. Using AMD's APU and ROCm, I was able to run large language models (LLMs) on this device, which is pretty impressive for something designed mainly for gaming. The key to making this work was the Steam Deck's unified memory architecture, which let me change how much memory the GPU could use. This flexibility was crucial for running complex models that needed more memory.
Comparing the Steam Deck to something like the Nvidia Jetson TX2, which is made for AI and machine learning, the Steam Deck really holds up. The Jetson TX2 is great for serious AI work, but the Steam Deck shows that even a gaming device can handle these heavy tasks. It's not just for playing games; it's powerful enough for advanced computing stuff too.
About how much free space do you need on your steam deck to do this? 20 gigs?
I am very excited to try this! Thank you for writing the guide.
Also in the "Install Distrobox and Podman" step the link for podman is deprecated. I am going to try using lilipod from here https://github.com/89luca89/lilipod/releases/download/v0.0.2/lilipod-linux-amd64
Another helpful detail, if someone goes through blindly punching in the commands at the "Let’s install RoCm, AMD’s GPU drivers/programming environment" step this link will fail
http://repo.radeon.com/amdgpu-install/latest/ubuntu/jammy/amdgpu-install_5.7.50700-1_all.deb
I don't know enough about this stuff to know whether you can assume the latest version of amdgpu will work, but if you want to link to the specific version in your blog post, this link is the permanent link
http://repo.radeon.com/amdgpu-install/5.7/ubuntu/jammy/amdgpu-install_5.7.50700-1_all.deb
This reddit thread also has some useful information to get started on trying different LLM models
https://www.reddit.com/r/LocalLLaMA/comments/18hzun0/sharing_a_simple_local_llm_setup/ specifically this quote below
--------------------------------
Steps:
Install llama.cpp, the steps are detailed in the repo.
Download an LLM from huggingface.
For those not familiar with this step, look for anything that has GGUF`in its name. You will probably find that on TheBloke's page. If you are not sure which one to choose, start with one that has lots of likes or downloads, or browse this community for impressions and feedback.Once you find the model you like, go to its page, click on `Files and versions` and then choose a file that ends with .gguf and download it. If you are not familiar with the sizes, go for Q4_K_M and make sure the size of the file seems to be something that can fit in your GPU or CPU memory.
Start the llama.cpp server, here is the command I use to start Mixtral with GPU:
./server -m ./mixtral-8x7b-instruct-v0.1.Q4_K_M.gguf --alias gpt-3.5-turbo --n-gpu-layers 10000 --mlock --port 3077 --cont-batching --ctx-size 4096
I started the server on port 3077, which means that the endpoint at `http://127.0.0.1:3077/v1/chat/completions` is up. In `Chatbox` UI, I can just go to settings and replace the API Host with `http://127.0.0.1:3077` and the app runs with my local model now.
-----------------